
My neighbor has a circular driveway…he can’t get out.
-Steven Wright
Welcome to the third installment in our miniseries about circularity. In the first, we looked broadly at circular definitions, both in everyday language and in mathematics. In the second, we tackled the surprisingly difficult task of establishing a non-circular definition for the simple-seeming notion of “finite set”. Today, we’re going to continue our discussion of finite sets, introducing a useful definition that at first glance appears circular but upon further analysis turns out to be on surprisingly solid foundations. (The contents of the previous posts are not at all necessary for understanding this one, so don’t worry of you’ve forgotton (or never read…) them.)
Let’s take a look at a few fine examples of finite sets. The empty set, 

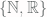

With this in mind, we might want to introduce a strengthening of the notion of “finite set” to rule out sets like
Attempted Definition 1: A set
is truly finite if it satisfies the following two properties:
- All of the elements of
This definition certainly rules out our set 


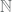

Attempted Definition 2: A set
- All of the elements of
- All of the elements of all of the elements of
Ok, but this was silly. We already knew that this definition wasn’t going to work for us, as something like 
Attempted Definition 3: A set
- All of the elements of
- All of the elements of all of the elements of
- And so on…
This definition is at least beginning to express the idea we’re grasping at, and we’re not going to be able to find any clear examples of sets that satisfy this definition and yet obviously should not be considered to be truly finite. We’re trying to write a precise mathematical definition, though, and the phrase “And so on…” is much too vague to be an acceptable part of our final definition.
We need to find a clear, concise way to make the intuition behind Attempted Definition 3 precise. It turns out there is a quite elegant solution. It also turns out that this is a fundamental notion in set theory and already has a name that is different from “truly finite”, so we’ll switch over now to its actual name: “hereditarily finite”.
(Actual!) Definition: A set
- All of the elements of
“Whoa, hold on a minute,” I can hear you saying. “This must be a joke. We’re in the third installment of a series on circular definitions, and you’re trying to pass of this clearly circular definition as an ‘actual’ mathematical definition? Nice try, but I’m not fooled.”
And I’ll admit that it does look as if we’re defining the term “hereditarily finite” in terms of … “hereditarily finite.” But this is in fact a perfectly fine definition, for reasons that those of you familiar with recursion in computer programming may already begin to see.
Let’s start with a small step and ask ourselves the simple question, “Are there any sets at all that we can unambiguously say are hereditarily finite according to the above definition?” Perhaps surprisingly, there are! Take a moment to try to think of one before reading on.
To find a set that is definitely hereditarily finite, let’s return to that most finite of all finite sets: the empty set. The empty set is clearly finite, so it satisfies Property 1 of our definition. What about Property 2? Well, the empty set doesn’t have any elements, so it’s vacuously true that all of its elements are hereditarily finite. (Indeed, any statement asserting something about all of the elements of the empty set is vacuously true. All of the elements of the empty set are the emperor of France. All of the elements of the empty set can make a rock so heavy that they can’t lift it.) The empty set therefore satisfies both properties of our definition, so the empty set is hereditarily finite!
Now that we know this, we can start building a veritable menagerie of hereditarily finite sets. Consider the set 




This is all well and good, but in order for our definition actually to do its job, we want something stronger to be true. We want it to be the case that, if somebody hands us an arbitrary set, we can definitively tell whether or not it is hereditarily finite. And there is in fact a step-by-step process for doing just this. Here it is (for concision, we will abbreviate “hereditarily finite” as “HF”):
To tell whether an arbitrary set
Step 0: If
Step 1: If any of the elements of
denote the set of all elements of elements of
Step 2: If any of the elements of
denote the set of all elements of elements of
…
Step n + 1: If any of the elements of
is infinite, then stop the process and conclude that
denote the set of all elements of elements of
…
We can get a good feel for what’s going on here by looking at this process in action for a couple of different sets. I think it’s instructive, but if you want to skip the details, you can scroll down to the next horizontal line.
First, consider the set 
In Step 1, we first note that all of the elements of 
In Step 2, we note that all of the elements of 
In Step 3, we note that all of the elements of 
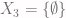
In Step 4, we note that all of the elements of
Next consider 
In Step 1, we note that all of the elements of 
In Step 2, we note that all of the elements of 
In Step 3, we note that, in fact, both elements of
In both cases above, our process halted after a relatively small number of steps, giving us an answer. Do we know that this process necessarily finishes, though? A priori, it looks possible that for certain sets it might just keep going on forever without yielding any conclusion about whether or not the set is hereditarily finite. It turns out, though, that (at least when working with the standard axioms for set theory) the process necessarily ends after a finite (though potentially arbitrarily large) number of steps, and that this fact is due to a rather curious axiom known as the Axiom of Foundation (sometimes called the Axiom of Regularity). It reads as follows:
The Axiom of Foundation: For every non-empty set
of
.
It might not immediately be obvious that this axiom implies that our process must eventually stop, or even that the axiom has anything to do with what we’ve been discussing today. And since this post is already way too long, I’m not going to give a proof here (maybe in a future post?). But it’s a direct consequence of the axiom (and indeed can even be seen as a kind of reformulation of the axiom) that, given any set
I want to say a few more words about this axiom to close, though. I introduced it as a “curious axiom”, and a reason for this is that, although the axiom is listed among the standard axioms of set theory, essentially all of mathematics can be developed entirely without using the Axiom of Foundation at all! Its raison d’être is simply that it makes sets nicer to work with! Sets that don’t satisfy the Axiom of Foundation are weird and pathological and, for most purposes, we’d rather just forget about them during our day-to-day lives. (There are certainly interesting things to say about axiom systems that don’t include the Axiom of Foundation or even include explicit anti-Foundation axioms, but we’ll leave that story for another day.)
One prominent potential set that the Axiom of Foundation rules out is the set 
In Step 1, we note that all of the elements of 

But now, since
So, is
Cover Image: “The Battle Between Carnival and Lent” by Pieter Bruegel the Elder

 and so on. Recalling the meaning of the graph, this means that the definition of
and so on. Recalling the meaning of the graph, this means that the definition of  contains
contains  , the definition of
, the definition of  , and so on.
, and so on.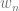 visited in our path itself has a definition, and therefore there are certainly arrows pointing out of the node associated with
visited in our path itself has a definition, and therefore there are certainly arrows pointing out of the node associated with 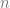 .
. such that
such that  and
and  is the same word as
is the same word as  . But in that case, look at what we have:
. But in that case, look at what we have: ;
; ;
; ;
; ).
).
 and
and 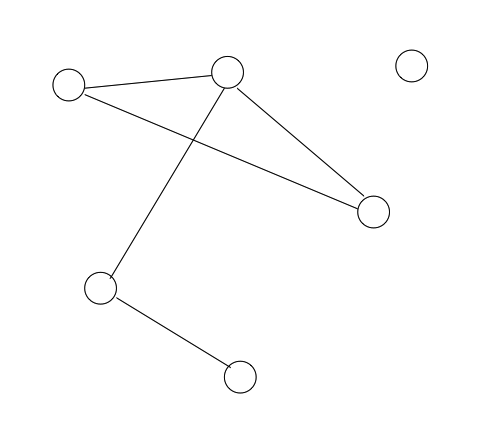
 , a subgraph
, a subgraph 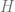 of
of 
 , is the least number of colors needed for a chromatic coloring of
, is the least number of colors needed for a chromatic coloring of 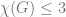 . It is not hard to show (Exercise: check this!) that it is impossible to construct a chromatic coloring of
. It is not hard to show (Exercise: check this!) that it is impossible to construct a chromatic coloring of  . Notice that the chromatic number of a graph
. Notice that the chromatic number of a graph  is a finite number, and, for every finite subgraph
is a finite number, and, for every finite subgraph 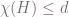 . Then
. Then  .
.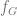 from the natural numbers to the natural numbers by letting
from the natural numbers to the natural numbers by letting  be the least number of vertices in a subgraph of
be the least number of vertices in a subgraph of  .
.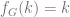 for every natural number
for every natural number  , then
, then  . This is because, if
. This is because, if  is a finite subgraph of
is a finite subgraph of 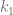 , then, by removing vertices from
, then, by removing vertices from  with chromatic number
with chromatic number  .
. , that means that any subgraph of
, that means that any subgraph of  is larger than the number of atoms in the observable universe, and
is larger than the number of atoms in the observable universe, and 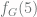 is inconceivably larger still. Intuitively, the faster
is inconceivably larger still. Intuitively, the faster 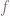 such if
such if 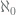 . All larger cardinalities are said to be uncountable. The smallest uncountable cardinal is
. All larger cardinalities are said to be uncountable. The smallest uncountable cardinal is  , the next smallest is
, the next smallest is  , and so on.
, and so on.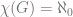 and
and 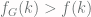 for all
for all  ).
).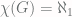 and
and  , which is a strengthening of the Continuum Hypothesis. They then perform a technique known as forcing to produce a model of set theory in which the E-H-S question has a positive answer. While their ideas ended up not being useful for the technical problem I was working on, while reading their proof, I had a vague feeling that I could combine some of their ideas with some ideas I had developed the previous fall to show that the forcing step of their proof was unnecessary. In other words, it seemed that maybe a positive answer to the E-H-S question already followed from
, which is a strengthening of the Continuum Hypothesis. They then perform a technique known as forcing to produce a model of set theory in which the E-H-S question has a positive answer. While their ideas ended up not being useful for the technical problem I was working on, while reading their proof, I had a vague feeling that I could combine some of their ideas with some ideas I had developed the previous fall to show that the forcing step of their proof was unnecessary. In other words, it seemed that maybe a positive answer to the E-H-S question already followed from 

 . This is a truly astounding number, dwarfing the estimated number of atoms in the observable universe (
. This is a truly astounding number, dwarfing the estimated number of atoms in the observable universe ( ) or the estimated number of legal positions in chess (a piddling
) or the estimated number of legal positions in chess (a piddling  ). The possibilities in go are, for all intents and purposes, infinite. No matter how much one learns, one knows essentially nothing.
). The possibilities in go are, for all intents and purposes, infinite. No matter how much one learns, one knows essentially nothing. that cannot be reached from below through the standard procedures of climbing to the next cardinal, applying cardinal exponentiation, or taking unions of a small number of small sets. (More formally,
that cannot be reached from below through the standard procedures of climbing to the next cardinal, applying cardinal exponentiation, or taking unions of a small number of small sets. (More formally, 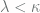 , we have
, we have 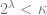 .)
.)
 ,
,
 ,
,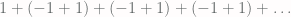
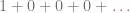 ,
,

 approach a fixed number
approach a fixed number 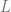 as
as  .
.
 . The lamp is half on and half off.
. The lamp is half on and half off.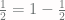 .
. in for
in for 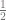 on the right side of this equation, he finds that
on the right side of this equation, he finds that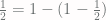 .
.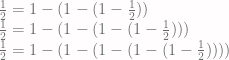 .
. .
. ,
, as above. Instead, one computes the limit of the average of the first
as above. Instead, one computes the limit of the average of the first 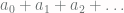 and initial sums
and initial sums 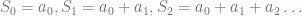 , one then defines a sequence
, one then defines a sequence  by letting
by letting .
. approach a fixed number
approach a fixed number  .
.

